Hey,
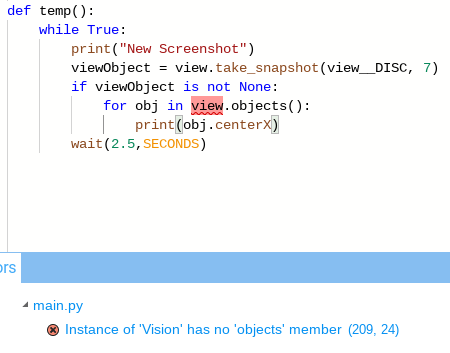
I’m programming for a new team to Vex, and I’ve been unable to get the vision sensor to return information concerning multiple objects in python. Using the sidebar, it shows only the functions largest_object() and take_snapshot(SIG) as functions with vision. However, in C++ a function, objects(), exists that returns an array of all objects seen by the vision sensor. In other threads I saw that this function existed in python, but I cannot get it to work now. I’m competing in VRC and am using Vexcode V5 from the chrome web store.
Any idea how to code a vision sensor to detect multiple objects in python?
Ok, that appears to have worked, or at least not generated any error on building. However, I looked over the guides the app had, and it doesn’t mention the fact take_snapshot(SIG) returns a tuple containing the different vision objects (Specifically, it just mentions that it “Takes a snapshot from the Vision Sensor”). Is there any primary place where I can find a more comprehensive set of documentation.
Thanks for the information.
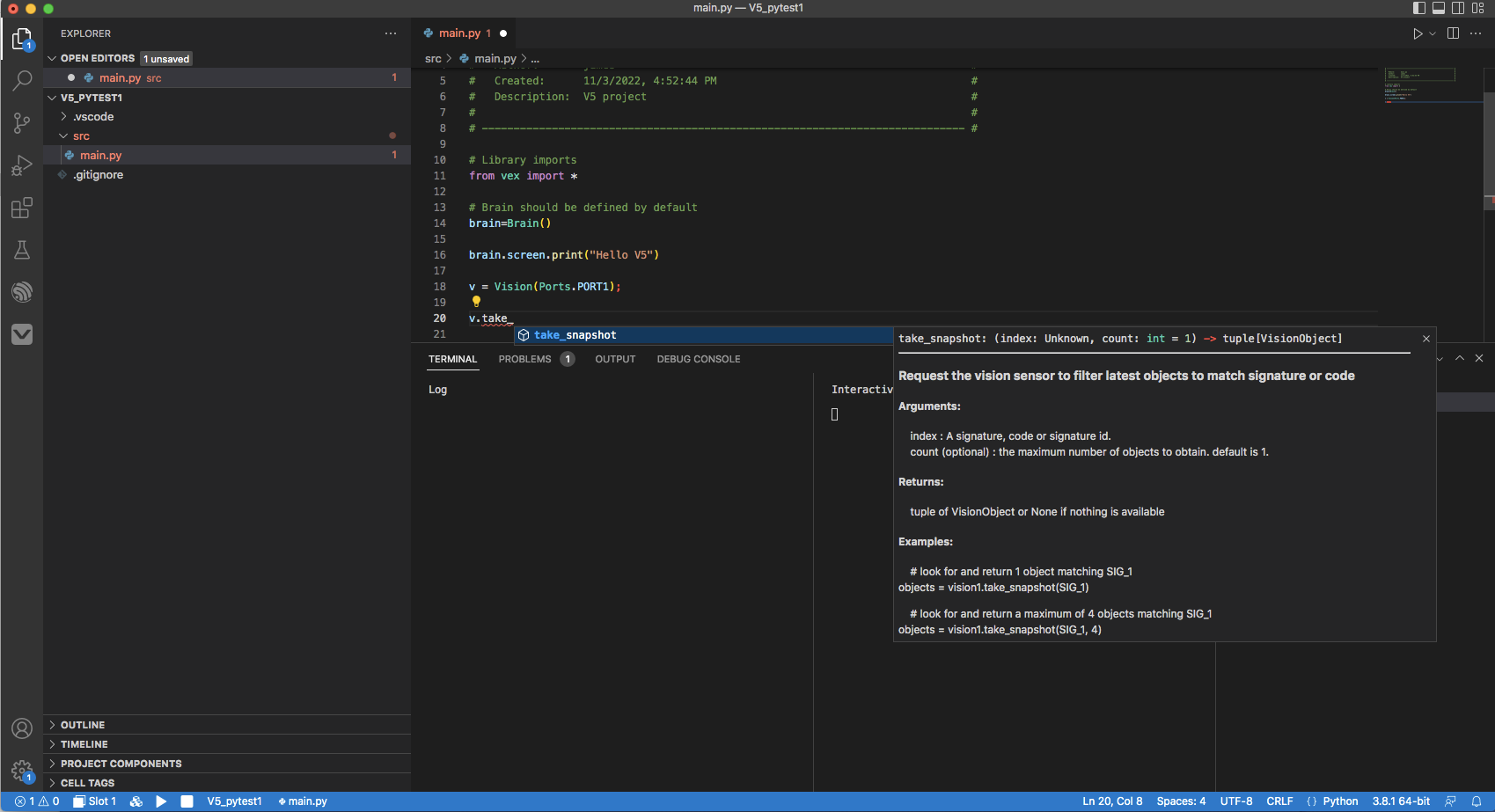
If you were programing using the Visual Studio Code extension then the intellisense would have helped.
Otherwise I’m not sure if/when VEXcode may improve its help system, and yes, help for take_snapshot in VEXcode Python is pretty useless.